
The Vivid Unknown
THE VIVID UNKNOWN
“There seems to be no ability to see beyond, to see that we have encased ourselves in an artificial environment that has remarkably replaced the original, Nature itself. We do not live with nature any longer; we live above it, off of it as it were. Nature has become the resource to keep this artificial or New Nature alive.”
- Godfrey Reggio

The Vivid Unknown is an AI-driven collective viewing experience - the interactive installation reimagines the seminal 1982 film Koyaanisqatsi in an immersive projection space centered on a generative AI model trained on the archives of Godfrey Reggio, exploring the tensions and violence between nature, humans, and technology.








The Vivid Unknown is a collective viewing experience that responds to audience engagement and evolves depending on the viewers' presence and proximity, and the choreography of their interactions with each other and the work. Using computer vision the interactive engine quantizes motion and body language from the participants using real-time skeletal pose detection, observing both time and activity in space.
Discrete body tracking allows for the identification of gestures and postures; by determining engagement and orientation of the viewer’s sightline, the system can calculate which screen the viewer is looking at, and more specifically what they’re looking at; when they move away from the content, it can trigger additional cues to try to keep them engaged. In quantifying the viewers’ movement and attention rate, the system can compute how still they are, how fast they're moving about, and when they might start to leave the installation it can trigger new content to pull them back in.
As more and more viewers enter it builds to a critical mass, then breaks down, like data deterioration, digital decay, or bit rot. The imagery takes on ghostly additive forms, almost fading to white, as the footage becomes more opaque, bursting into an unintelligible, liminal state; then silent. Then it resets. As if a fleeting glimpse of where civilization could be heading.


Working with footage from the Qatsi trilogy we have created a new neural network model mined of imagery from the Reggio archive to generate never before seen footage. By analyzing the pixels, patterns, features, and correlations within the data we’ve enabled the possibility to generate new images in the style of the films. This model has been analyzed with CLIP (Contrastive Language–Image Pre-training) software to learn the visual concepts via natural language supervision; in turn the software has generated new layers of content, a machine-learning chimera of Koyaanisqatsi. The work is divided into nature, humans, and technology and the various combinations of each.









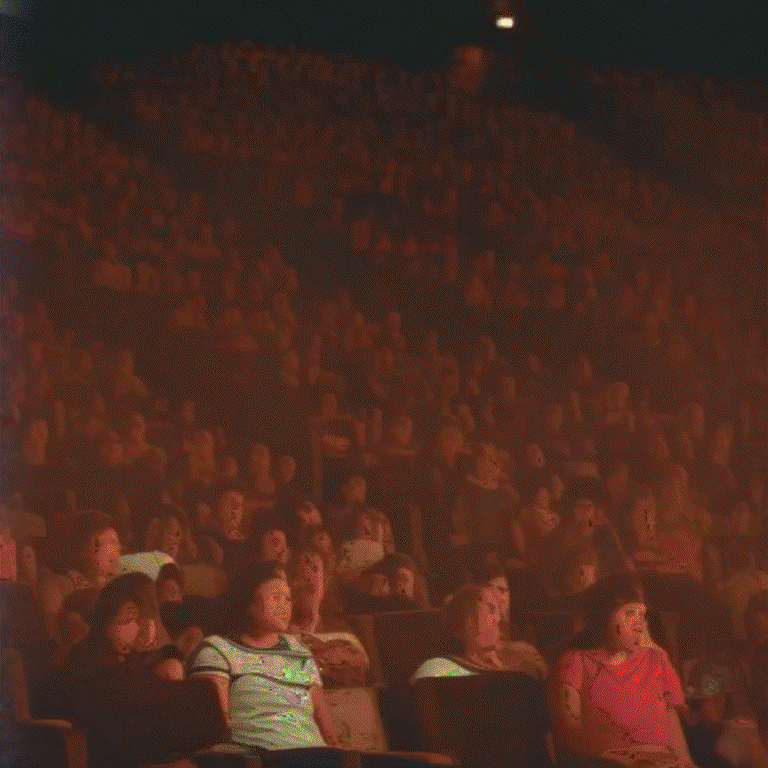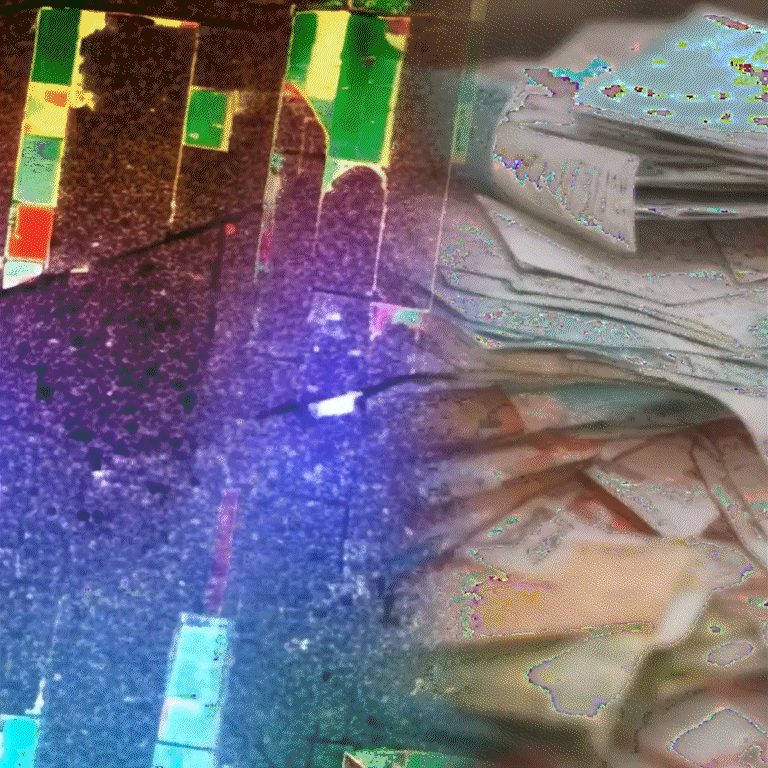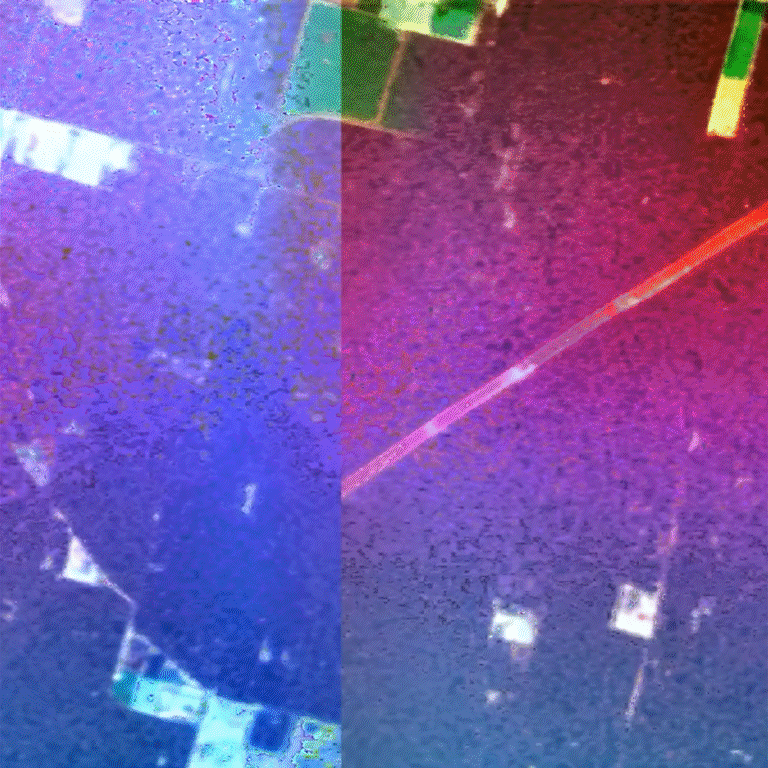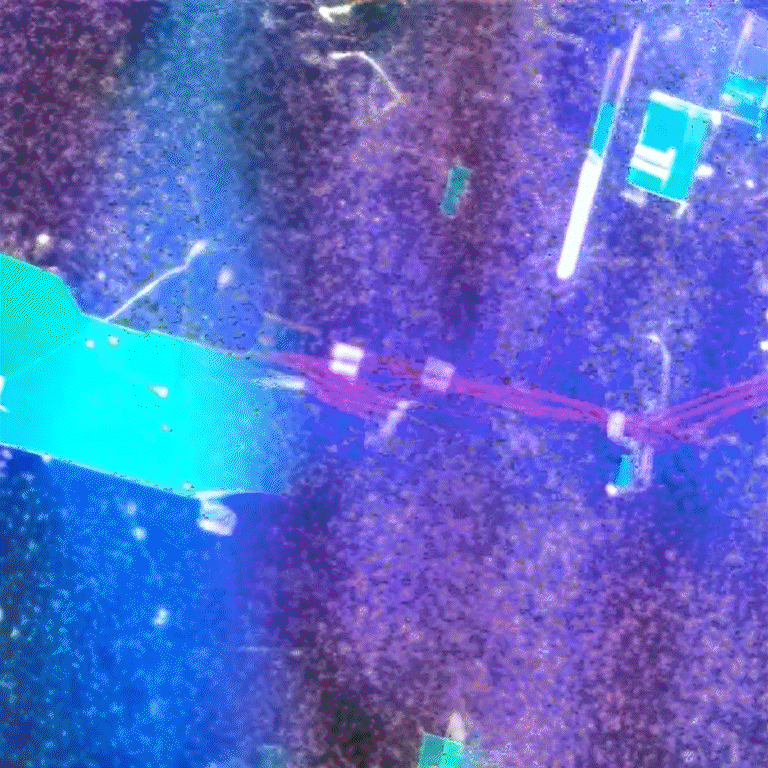



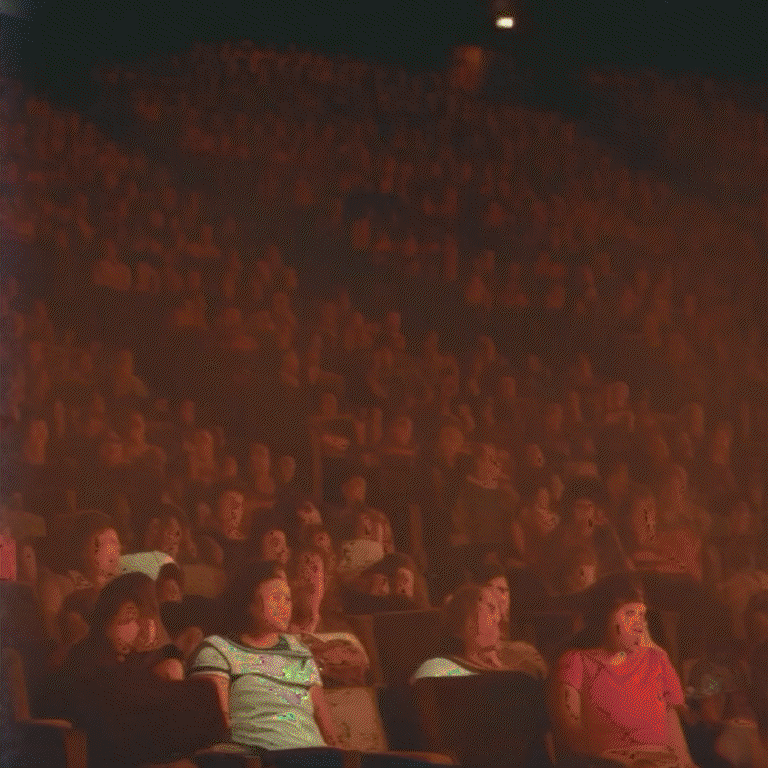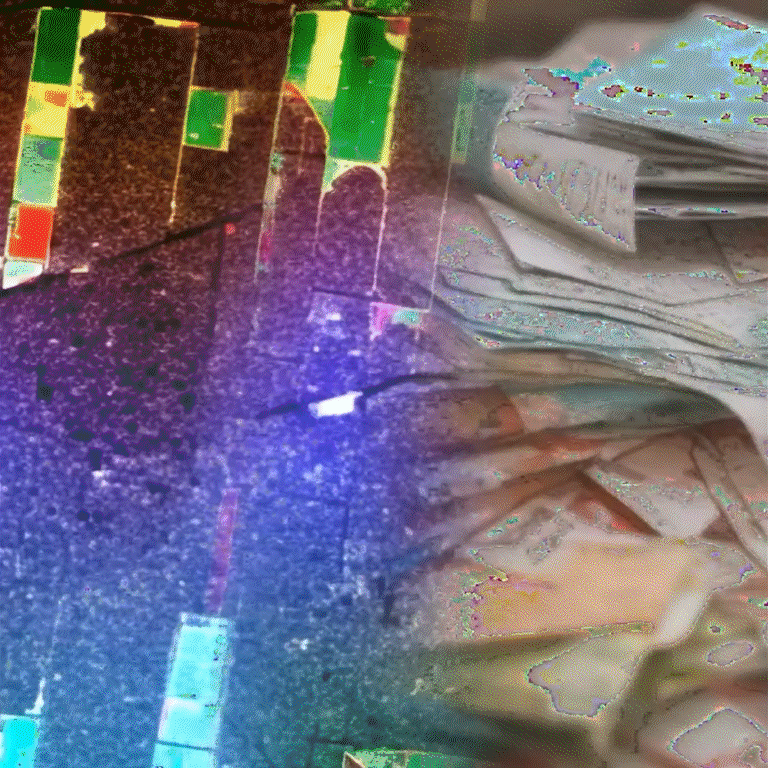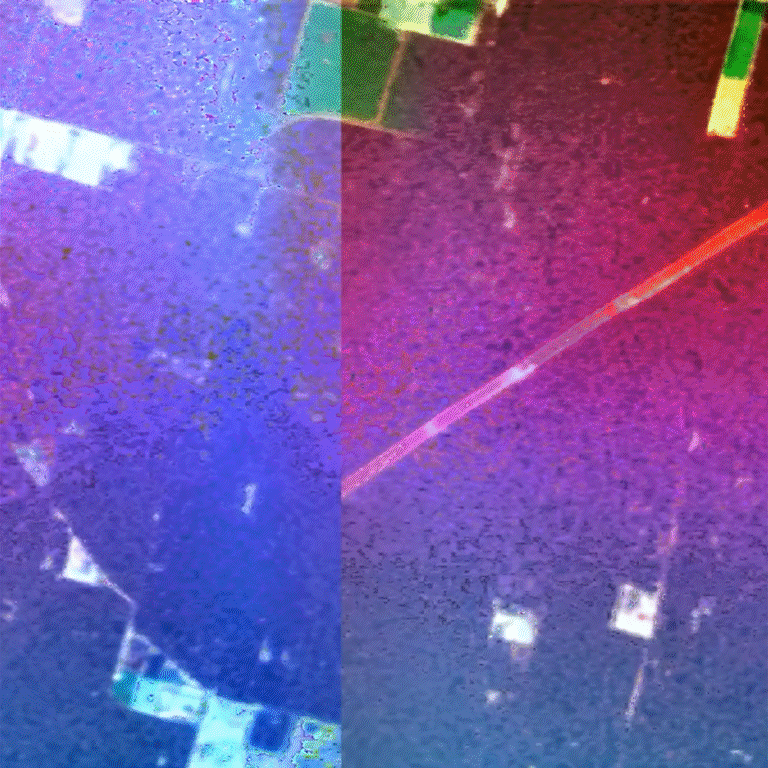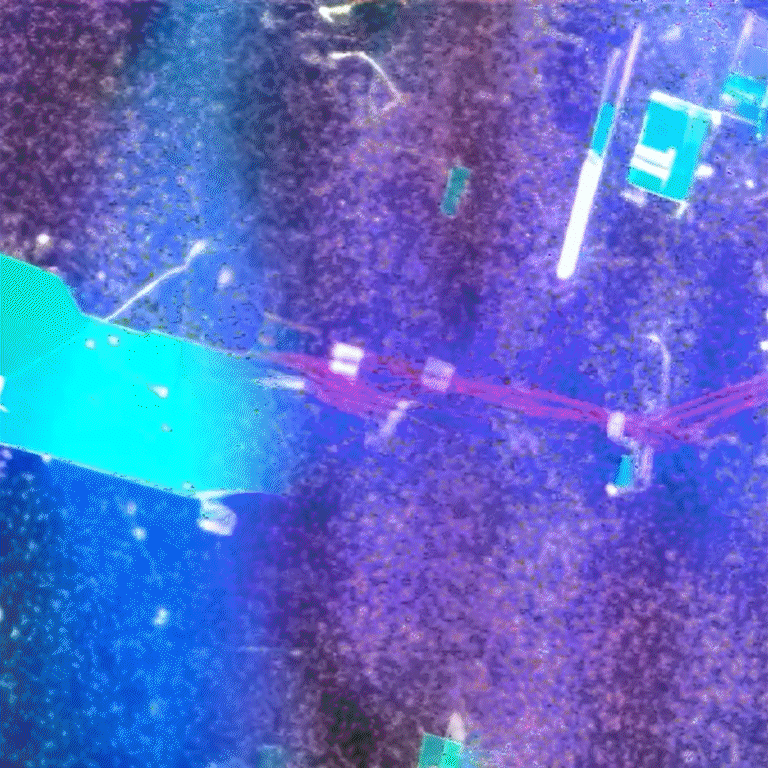



Directed by Godfrey Reggio and John Fitzgerald
Technical Direction by Dan Moore
Sound Design by Matt Tierney
Powered by Foundry.
Supported by Onassis ONX Studios.
Produced by Sensorium, Jazia Hammoudi, Dan Moore, Pierre Zandrowicz, Matt Tierney, Graham Milliken, and Laura Ulanova.







